Batch Insert Hive
Hives support of data partitioning offers a simple and effective solution. It allows us to impose batch level transaction semantics onto our data.
Error In Batch Job Writing To Hive Talend Community
If the bulk mutation map reduce is the only way data is being merged then step 1 needs to be performed only once.

Batch insert hive. You use insert instead of overwrite here to show the option of inserting instead of overwriting. It generates a separate insert per row which causes hive to create a mr job for each row. Finally note in step g that you have to use a special hive command service rcfilecat.
With partitioning we define the hive tables as usual except that one or more elements that would normally be defined as columns are instead defined as partition keys. If hive sync is enabled in the deltastreamer tool or datasource the dataset is available in hive as a couple of tables that can now be read using hiveql presto or sparksqlsee here for more. Hive allows only appends not inserts into tables so the insert keyword simply instructs hive to append the data to the table.
Starting with hive 0130 the select statement can include one or more common table expressions ctes as shown in the select syntax. For an example see common table expression. Iam trying to insert 200000 records into hive text table using jdbc driver and sql insert statements.
This page explains how to use hive to bulk load data into a new empty hbase table per hive 1295. When issuing an upsert operation on a dataset and the batch of records provided contains multiple entries for a given key then all of them are. To use the bulk insert task to transfer data from other database management systems dbmss you must export the data from the source to a text file and then import the data from the text file into a sql server table or view.
Hive can insert data into multiple tables by scanning the input data just once and applying different query operators to the input data. Pyhive seems to try to get a result set after each insert and does not get one breaking the executemany. How does hudi handle duplicate record keys in an input.
If youre not using a build which contains this functionality yet youll need to build from source and make sure this patch and hive 1321 are both applied. Treating the output of map reduce step 2 as hive table with delimited text storage format run insert overwrite to create hive tables of desired storage format. I use statementaddbatch method and executebatch per 9000 rows.
Ive tried to use 15 000 or 20 000 batch size but i cant get a res. Now it takes 60 seconds for every 9000 rows insertion. The bulk insert task can transfer data only from a text file into a sql server table or view.
But there is another issue which is that this is not performant at all in the way the batch insert is generated.

Hbase Write Using Hive
Ph Table

Running Apache Hive 3 New Features And Tips And Tricks Adaltas

Hiveacidpublic

Flink And Hive Integration Unifying Enterprise Data Processing Syst

Transactional Sql In Apache Hive
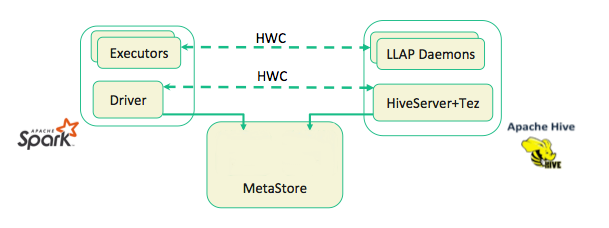
Using The Hive Warehouse Connector With Spark

Hive Batch And Interactive Sql On Hadoop By Alan Gates At Big

Performance Tuning In Hive Bigdatalane Your Lane Of Success