Batch Insert Redshift
This means there is an obvious need to insert rows of data into redshift continuously depending on the incoming data rate. For example the following insert statement selects all of the rows from the category table and inserts them into the categorystage table.
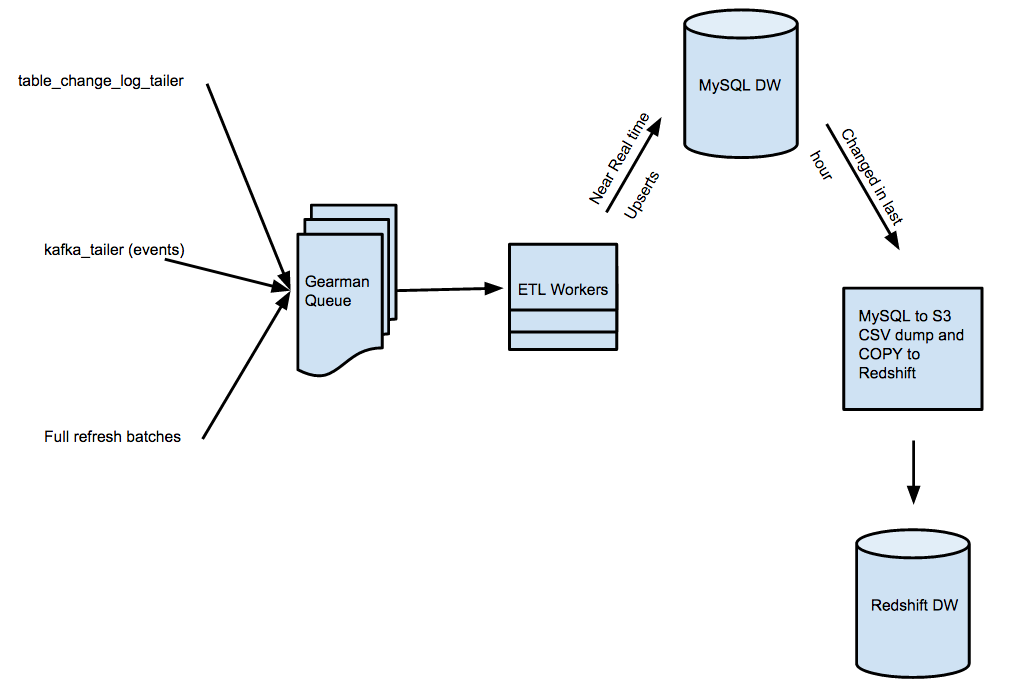
Streaming Messages From Kafka Into Redshift In Near Real Time
Alternatively if your data already exists in other amazon redshift database tables use insert into select or create table as to improve performance.

Batch insert redshift. Use a bulk insert operation with a select clause for high performance data insertion. This section presents best practices for loading data efficiently using copy commands bulk inserts and staging tables. How to insert in redshift.
Instead redshift offers the copy command provided specifically for bulk inserts. Using individual insert statements to populate a table might be prohibitively slow. Catid catgroup catname catdesc.
These differences need to be taken into account to design tables and queries for optimal performance. Insert into categorystage values 14 default default default 15 default default default. Use a multi row insert.
Select from categorystage where catid in 1415 order by 1. The first example inserts specific catid values for two rows and default values for the other columns in both rows. Loading very large datasets can take a long time and consume a lot of computing resources.
Redshift insert into need being a data warehouse offered as a service redshift is typically used as part of an extract transform load pipeline. The simplest way to insert a row in redshift is to to use the insert into command and specify values for all columns. Use the insert and create table as commands when you need to move data or a subset of data from one table into another.
Constraints arent enforced redshift doesnt enforce primary or foreign key constraints. It lets you upload rows stored in s3 emr dynamodb or a remote host via ssh to a table. If a copy command is not an option and you require sql inserts use a multi row insert whenever possible.
Data compression is inefficient when you add data only one row or a few rows at a time. This makes batch inserts fast but makes it easy to accidentally cause data quality issues via duplication or foreign key violations. If you want to insert many rows into a redshift table the insert query is not a practical option because of its slow performance.
We strongly encourage you to use the copy command to load large amounts of data. If you have 10 columns you have to specify 10 values and they have to be in order how the table was defined. Multi row inserts improve performance by batching up a series of inserts.
How your data is loaded can also affect query performance.

14 Best Practices For Amazon Redshift Performance Optimization

Heimdall Proxy For Amazon Redshift Overview Heimdall Blog
Pl Sql Conversion Example Full360 Sneaql Wiki Github

Common Redshift Pitfalls And How To Avoid Them Heap
Aws Glue

Loading Amazon Redshift Data Utilizing Aws Glue Etl Service

14 Best Practices For Amazon Redshift Performance Optimization

A Brief Summary Of Compound Sort Key And Interleaved Sort Key With

How To Load Data Into Amazon Redshift Blendo Co